
This is Brad DeLong's Grasping Reality—my attempt to make myself, and all of you out there in SubStackLand, smarter by writing where I have Value Above Replacement and shutting up where I do not… Well! I Am Finally Optimistic About the SubTuringBradBot Project!: Monday MAMLMsModern Advanced Machine-Learning Models, that is. Hitherto it has mostly been failure modes of various kinds, and while the failure modes have been very interesting, as to the current limitations...
Modern Advanced Machine-Learning Models, that is. Hitherto it has mostly been failure modes of various kinds, and while the failure modes have been very interesting, as to the current limitations of GPTLLM MAMLMs software technology, they have kept me from getting to a point at which I would be all happy, recommending that students seeking a quicker answer to a question they have about what I think consult SubTuringBradBot rather than getting into the personal or the zoom office-hours line. But now I think I can recommend it for first-line questions. Plus an aside on the absurd inefficient ignorant overkill of “modern AI”…And so this is now nice to see: A sample:
Now crossing my fingers. What I want here is a natural-language interface to a structured “catechism” question-and-answer challenge-and-response database built from my analytical and historical judgments. I really do not want a GPT—General-Purpose Transformer—LLM—Large Language Model—to give me the most accurate flexible-function simulation it can of a typical internet s***poster. I do not want that even if that has overlaid on top of it a “quality of answer” metric derived from some form of RLHF. What I want, essentially, is RAG with a thin natural human-language affordance layer on top of it, since keyword searching is something of a black art that few people are expert in. And now, until something else goes wrong, it looks like we are almost all the way there. Vain look, probably. Vain hope, perhaps. But that I no longer see obvious failure modes is very interesting. (The latest failure mode I think I have managed to scotch is Anthropic’s Claude Sonnet tendency to go off the rails and start an unhinged rant, given any excuse, about how inadequate and prone to hallucinations its competitors’ models all just happen to be.) Not to mention it is a completely inefficient energy‑hungry resource-using mess. And so I find myself excited, skeptical, and more than a little bemused. Why bemused? Well, there is a strong sense in which GPT LLM MAMLM’s are absurd overkill. Consider last week. I asked:
That is, alternatively, and more simply for people for whom UNIX is their native tongue:
The UNIX shell receiving and then executing this command is absolutely trivial in terms of its use of the machine’s hardware, software, and power resources. And yet, with the natural-language version, when I ask “What is on the grocery list?”, this happens:
You may ask: What is going on here? What is this dashboard result supposed to tell me? There is a sense in which GPT-LLM, MAMLM’s, are absurd overkill. Consider last week. I asked:
That is, alternatively, and more simply for people for whom UNIX is their native tongue:
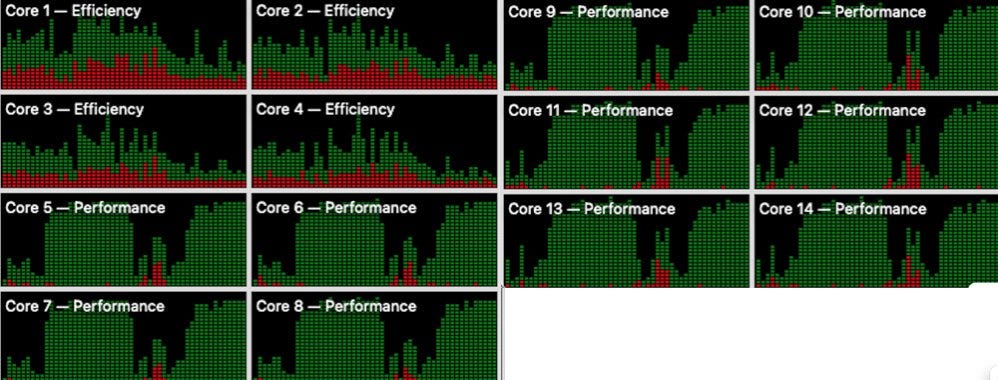
The UNIX shell receiving and then executing this command is absolutely trivial in terms of its use of the machine’s hardware, software, and power resources. By contrast, the chart above is what happens when I ask the same question in natural language of my local assistant on the MacStudio. First, a word about the machinery: The MacStudio’s main processor, its CPU, has fourteen sub-execution units that can work in parallel on one single chip, fourteen “cores”. Four of them are so‑called “efficiency” cores: relatively (relatively! each with more computing power than existed in the world in 1965!) small, low‑power units that sip electricity and quietly keep the operating system and background tasks going. The other ten are “performance” cores: larger, hotter, much more power-hungry units that can do a great deal of computation very fast—when they are actually asked to do anything at all. In the machine’s ordinary idle state, while I am simply accessing programs and typing commands, without attempting to access and engage any LLM, the ten performance cores simply twiddle their digital thumbs. The four efficiency cores are doing work: they are reasonably busy running the operating system (those show up as red bars on the activity chart) and whatever I, the user, have in the foreground and background (those show up as green bars)—mail, browser tabs, little daemons checking for updates, that sort of thing. Then I engage the LLM with: “What is on the current grocery list?” Somewhere in memory there is a file called grocery-list.md, sitting in a directory that various little programs are supposed to write to. What I want, in structural terms, is trivial: read that file and send its contents to my main Telegram channel. That is what the one‑line UNIX shell command above does. But what actually happens is that the Google gemma LLM model—an enormous roiling boil of linear algebra squatting in roughly 19 gigabytes of the MacStudio’s memory—receives the question. It swings into action. Within a second or two, all ten performance cores ramp from near-idle to 90–100 percent utilization. For the next three minutes they are maxxxed out, all ten of them being hammered, chewing on floating‑point operations as fast as Apple’s designers told TSMC’s fabrication lines to carve doped circuit paths on silicon crystal using ASML’s lithography machines will allow. The maxxximal technological achievement of the human race right now. Not on this part of the dashboard, but as real: the same thing is happening over on the graphics side. The GPU, a whole additional bank of 40 specialized cores intended for massively parallel arithmetic, also gets hammered for those three minutes. CPU and GPU together are, for a little while, fully loaded and doing ten times as much raw computation as all of the computers in the world in 1986 could have done had they all been maxed out, simply in order to decode one short English sentence into the underlying intent:
At the end of those three minutes, the machine has figured it out. Lo and behold, the contents of grocery-list.md duly appeared in the main Telegram channel. Ten times as much computing power as existed in the world in 1985. Devoted to making sense of the natural-language sentence: “What is on the grocery list?” And taking three full minutes to do so. My brain burns 50 watts of power. If I want to look at the grocery list, I turn my head and point my eyes at the refrigerator door. Maybe 1% of my brain’s power to form that intenstion and direct that action? For one second? A power budget of 50 x .01 x 1 = 0.5W-seconds. And the same brain-effort if I insisted on doing the task in the virtual rather than in the real world, if I were a natural speaker of UNIX. But for the MacStudio? 140 watts. 3 minutes: 140 x 3 x 60 = 7W-hours, 50000 times as much. And if I were not to have run the LLM on device, but instead to have sent it out to Anthropic and insisted on running it on their top-line opus LLM model? My guess is that we would be at 0.14kW-hours: 1,000,000 times as much as me simply using my wetware, the standard cognitive-processing toolkit of the literate language-using East African Plains Ape. And note that it is not that computers are inefficient at tasks like printing grocery lists to Telegram messaging channels. Computers are actually very good at this. That’s what we designed them to do: move symbolic information around and remix it. What is it then? It is the GPT LLM MAMLMs that are hopelessly inefficient at this. And it is because they are hopelessly inefficient at this that, right now, RAM and GPU prices are screamingly high. It is not there are tremendously valuable things that LLMs are doing. But a number of very large companies are now betting that there will be such things, and that they need to get cracking now to have an advantageous competitive position when these truly useful things GPT LLM MAMLMs do arrive. The datacenter infrastructure boom is the result of company executives applying truly enormous amounts of brute financial force to try to overcome the massive inefficiencies generated by our near-complete ignorance of how to do interpretation and generation of natural-language human communication at all efficiently. It is truly a remarkable timeline, this one we are in. So what follows from all of this, other than that when I swing back into the classroom in the spring for a large lecture class, I will offer a SubTuringBradBot option for office hours, and offer extra credit points to students who engage with it and then write up their thoughts on the engagement? And that Google Gemma on-device should be good enough for the job? I am not sure. If reading this gets you Value Above Replacement, then become a free subscriber to this newsletter. And forward it! And if your VAR from this newsletter is in the three digits or more each year, please become a paid subscriber! I am trying to make you readers—and myself—smarter. Please tell me if I succeed, or how I fail…##well-i-am-finally-optimistic-about-the-subturingbradbot-project-monday-mamllms
|

|
||||||||||
![]()
![]()











No comments:
Post a Comment