
Must-Read Books for High-Performance System Design (Sponsored)Access 4 PDFs on building and optimizing data-intensive applications.
Read experts’ proven strategies for optimizing data-intensive applications, database performance, and latency:
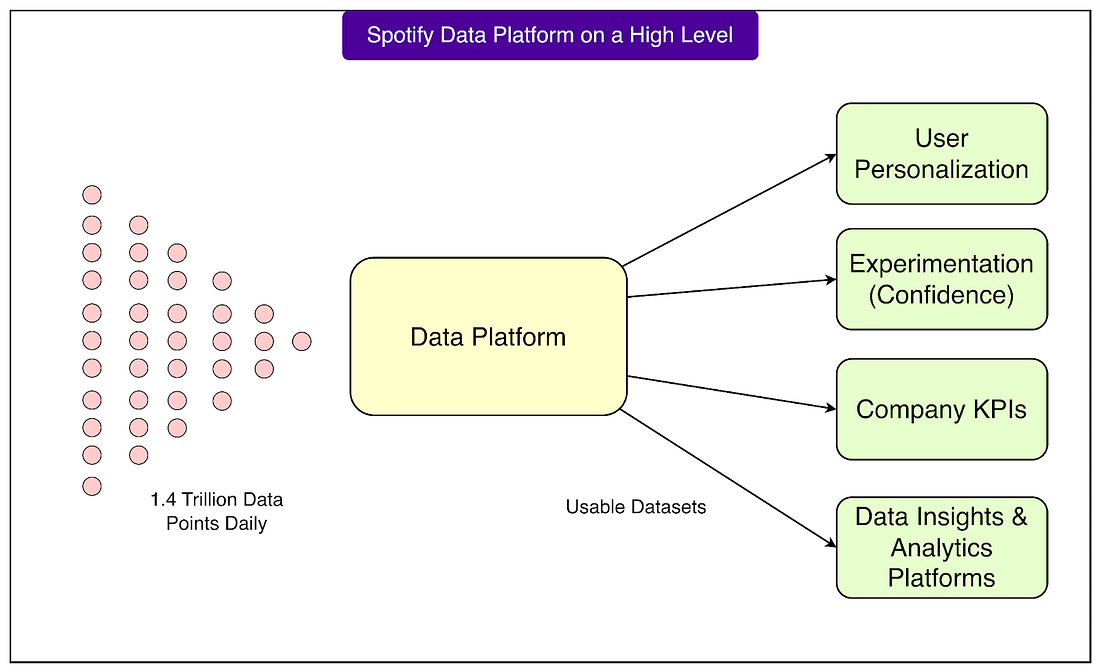
Whether you’re working on large-scale systems or designing distributed data architectures, these books will prepare you for what’s next. Disclaimer: The details in this post have been derived from the details shared online by the Spotify Engineering Team. All credit for the technical details goes to the Spotify Engineering Team. The links to the original articles and sources are present in the references section at the end of the post. We’ve attempted to analyze the details and provide our input about them. If you find any inaccuracies or omissions, please leave a comment, and we will do our best to fix them. Every day, Spotify processes around 1.4 trillion data points. These data points come from millions of users around the world listening to music, creating playlists, and interacting with the app in different ways. Handling this volume of information is not something a few ad hoc systems can manage. It requires a robust, well-designed data platform that can reliably collect, process, and make sense of all this information. From payments to personalized recommendations to product experiments, almost every decision Spotify makes depends on data. This makes its data platform one of the most critical parts of the company’s overall technology stack. Spotify did not build this platform overnight. In the early years, data systems were more improvised. As the company grew, the number of users increased, and the complexity of business decisions became greater. Different teams began collecting data for their own needs. Over time, this led to a growing need for a centralized, structured, and productized platform that could support the entire company, not just individual teams. The shift toward a formal data platform was driven by both business and technical factors:
This evolution happened organically as Spotify’s products matured. With each new feature and business need, new data requirements emerged. Over time, this learning process shaped a platform that now supports everything from real-time streaming analytics to large-scale experimentation and machine learning applications. In this article, we will look at how Spotify built its data platform and the challenges it faced along the way.
State of Trust: AI-driven attacks are getting more sophisticated (Sponsored)
AI-driven attacks are getting bigger, faster, and more sophisticated—making risk much more difficult to contain. Without automation to respond quickly to AI threats, teams are forced to react without a plan in place. This is according to Vanta’s newest State of Trust report, which surveyed 3,500 business and IT leaders across the globe. One big change since last year’s report? Teams falling behind AI risks—and spending way more time and energy proving trust than building it.
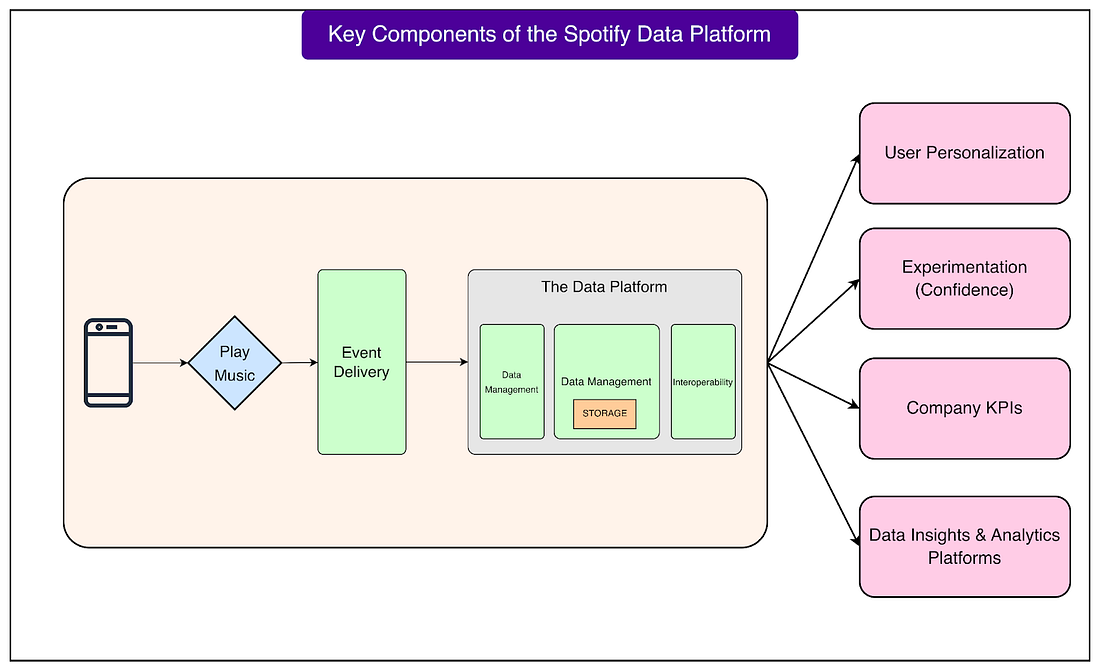
Get the full report to learn how organizations are navigating these changes, and what early adopters are doing to stay ahead. Platform Composition and EvolutionIn its early years, Spotify’s data operations were run by a single team. At one point, this team was managing Europe’s largest Hadoop cluster. For reference, Hadoop is an open-source framework used to store and process very large amounts of data across many computers. At that stage, most data work was still centralized, and many processes were built manually or handled through shared infrastructure. As Spotify grew, this model became too limited. The company needed more specialized tools and teams to handle the increasing scale and complexity. Over time, Spotify moved from that single Hadoop cluster to a multi-product data platform team. This new structure allowed them to separate the platform into clear functional areas, each responsible for a specific part of the data journey. At the core of Spotify’s platform are three main building blocks that work together:
These three areas are not isolated. They are deeply interconnected, forming a platform that is reliable, searchable, and easy to build on. See the diagram below that shows the key components of the data platform:
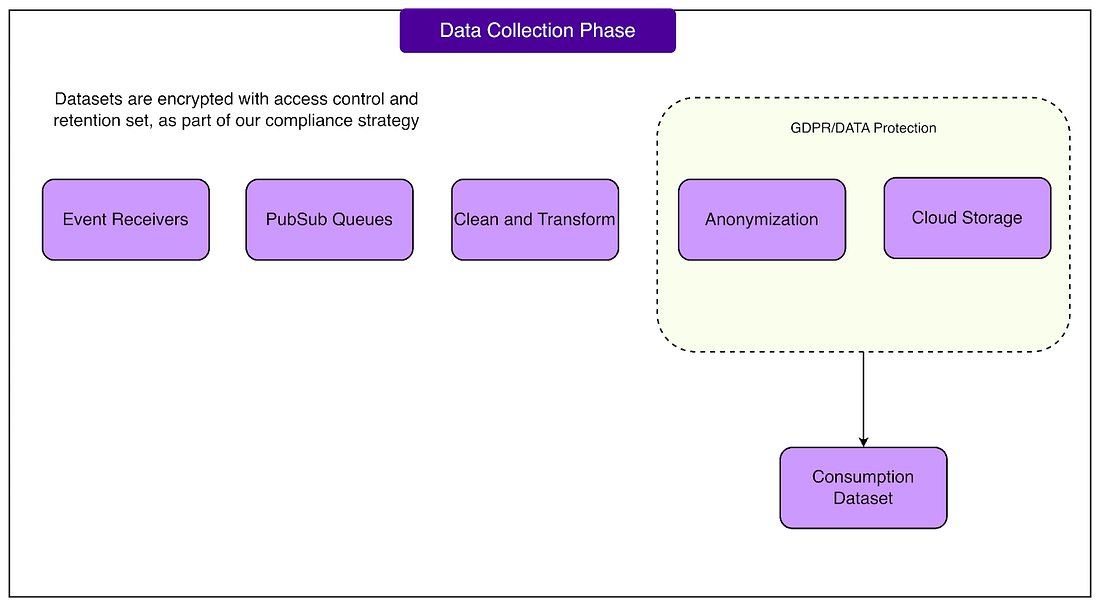
For example, once data is collected and processed, it becomes searchable and can be used directly in other systems. One of the most important systems it powers is Spotify’s experimentation platform, called Confidence. This platform allows teams to run A/B tests and other experiments at scale, ensuring new product features are backed by real data before being fully launched. Data Collection - Event Delivery at ScaleOne of the most impressive parts of Spotify’s data platform is its data collection system. Every time a user interacts with the app, whether by hitting play, searching for a song, skipping a track, or creating a playlist, an “event” is generated. Spotify’s data collection system is responsible for capturing and delivering all of these events reliably and at a massive scale. Spotify collects more than one trillion events every day. This is an extraordinary amount of data flowing in constantly from mobile apps, desktop clients, web players, and other connected devices. To handle this, the architecture of the data collection system has evolved through multiple iterations over the years. Early versions were much simpler, but as the user base and product features expanded, the system had to be redesigned to keep up with growing scale and complexity. How Developers Work with Event DataAt Spotify, product teams don’t need to build custom infrastructure to collect events. Instead, they use client SDKs that make it easy to define what events should be collected. Here’s how the workflow looks:
See the diagram below:
This level of automation is made possible through Kubernetes Operators. An operator is a special kind of software that manages complex applications running on Kubernetes, which is the container orchestration system Spotify uses to run its services. In simple terms, operators allow Spotify to treat data infrastructure as code, so changes are applied quickly and reliably without manual work. Built-in Privacy and SecurityHandling user data at this scale comes with serious privacy responsibilities. Spotify builds anonymization directly into its pipelines to ensure that sensitive information is protected before it ever reaches downstream systems. They also use internal key-handling systems, which help control how and when certain pieces of data can be accessed or decrypted. This is essential for compliance with privacy regulations like GDPR and for maintaining user trust. Centralization and Self-ServiceA key strength of Spotify’s data collection system is its ownership model. Instead of making the central infrastructure team responsible for every change, Spotify has designed the platform so that product teams can manage most of their own event data. This means a team can:
They can do all this without depending on the central platform team. This balance between centralization and self-service helps the platform scale to thousands of active users inside the company while keeping operational overhead low. Breadth of Event TypesThe platform currently handles around 1,800 different event types, each capturing different kinds of user interactions and system signals. There are dedicated teams responsible for:
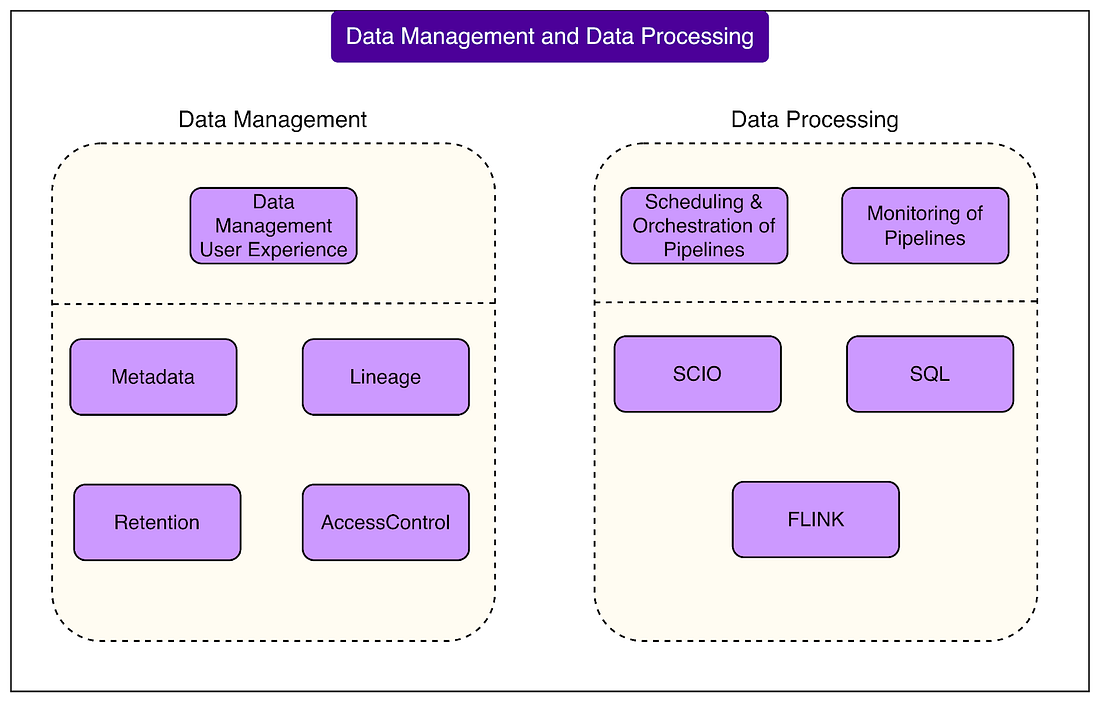
This massive, well-structured data collection layer forms the foundation of Spotify’s entire data platform. Without it, the rest of the platform (processing, management, analytics, and experimentation) would not be possible. It ensures that the right data is captured, secured, and made available at the right time for everything from recommendations to business decisions. Data Management and Data ProcessingOnce data is collected, Spotify needs to transform it into something meaningful and trustworthy. This is where data processing and management come into play. At Spotify’s scale, this is a massive and complex operation that must run reliably every hour of every day. Spotify runs more than 38,000 active data pipelines on a regular schedule. Some run hourly, while others run daily, depending on the business need. A data pipeline is essentially an automated workflow that moves and transforms data from one place to another. For example:
Operating this many pipelines requires a strong focus on scalability (handling growth efficiently), traceability (understanding where data comes from and how it changes), searchability (finding the right datasets quickly), and regulatory compliance (meeting privacy and data retention requirements).
The Execution StackTo run these pipelines, Spotify uses a scheduler that automatically triggers workflows at the right times. These workflows are executed on:
Most pipelines are written using Scio, a Scala library built on top of Apache Beam. Apache Beam is a framework that allows developers to write data processing jobs once and then run them on different underlying engines like Flink or Dataflow. This gives Spotify flexibility and helps standardize development across teams. Each pipeline in Spotify’s platform produces a data endpoint. An endpoint is essentially the final dataset that other teams and systems can use. These endpoints are treated like products with well-defined characteristics:
Platform as CodeSpotify has built the platform in a way that allows engineers to define their pipelines and endpoints as code. This means all configuration and resource definitions are stored in the same place as the pipeline’s source code. As mentioned, the system uses custom Kubernetes Operators to manage this. When developers push updates to their code repositories, the operators automatically deploy the necessary resources. This code ownership model ensures that the team responsible for a pipeline also controls its configuration and lifecycle, reducing dependency on centralized teams. With tens of thousands of pipelines, keeping everything healthy and efficient is a major priority. Spotify has a strong operations and observability layer that includes:
Backstage is an internal developer portal that Spotify open-sourced. It brings together tools for monitoring, cost analysis, quality assurance, and documentation. Instead of searching across many systems, engineers can manage everything from one central place. ConclusionSpotify’s data platform is a great example of how a company can evolve its infrastructure to meet growing business and technical demands. What began as a small team managing an on-premises Hadoop cluster has grown into a platform run by more than a hundred engineers, operating entirely on Google Cloud. This transformation did not happen overnight. Spotify aligned its organizational needs with its technical investments, defined clear goals, and built strong feedback channels with its internal users. By starting small, iterating, and learning from each stage of growth, they created a platform that balances centralized infrastructure with self-service capabilities for product teams. Other organizations can take valuable lessons from this journey. A dedicated data platform becomes essential when:
References: SPONSOR USGet your product in front of more than 1,000,000 tech professionals. Our newsletter puts your products and services directly in front of an audience that matters - hundreds of thousands of engineering leaders and senior engineers - who have influence over significant tech decisions and big purchases. Space Fills Up Fast - Reserve Today Ad spots typically sell out about 4 weeks in advance. To ensure your ad reaches this influential audience, reserve your space now by emailing sponsorship@bytebytego.com.
|
How Spotify Built Its Data Platform To Understand 1.4 Trillion Data Points
Tuesday, 11 November 2025


Subscribe to:
Post Comments (Atom)











No comments:
Post a Comment