
Get first access to the Second Edition of Designing Data-Intensive Applications [O’REILLY] (Sponsored)Start reading the latest version of the book everyone is talking about.
The second edition of Designing Data-Intensive Applications was just published – with significant revisions for AI and cloud-native! Martin Kleppmann and Chris Riccomini help you navigate the options and tradeoffs for processing and storing data for data-intensive applications. Whether you’re exploring how to design data-intensive applications from the ground up or looking to optimize an existing real-time system, this guide will help you make the right choices for your application.
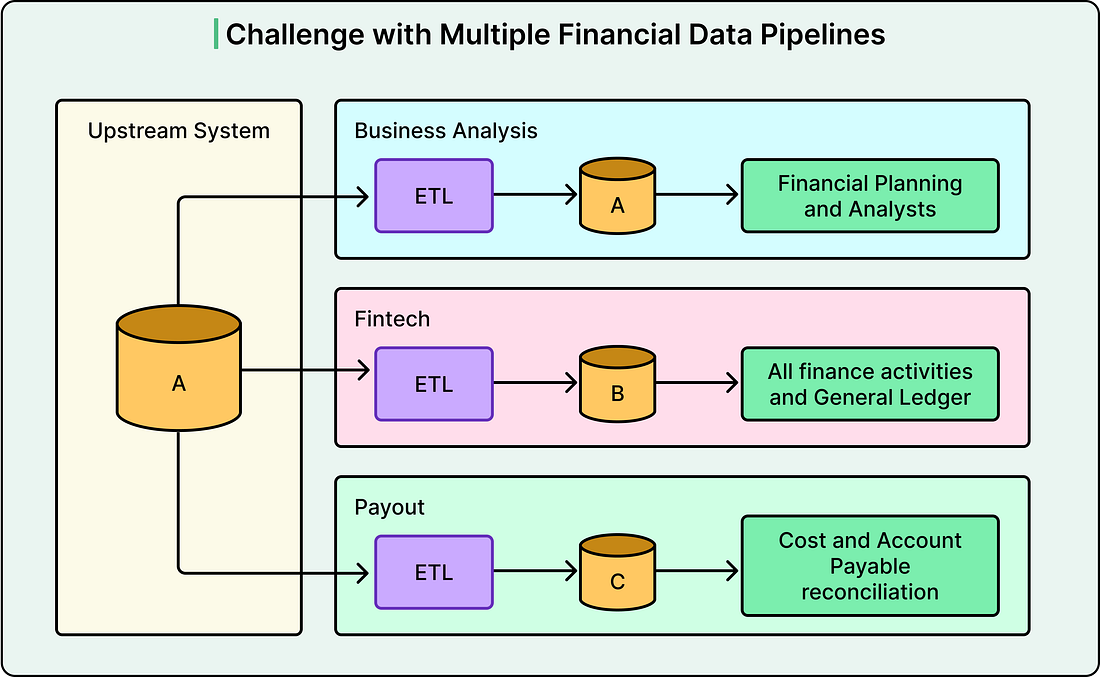
We’re offering 3 complete chapters. Start reading it today. Agoda generates and processes millions of financial data points (sales, costs, revenue, and margins) every day. These metrics are fundamental to daily operations, reconciliation, general ledger activities, financial planning, and strategic evaluation. They not only enable Agoda to predict and assess financial outcomes but also provide a comprehensive view of the company’s overall financial health. Given the sheer volume of data and the diverse requirements of different teams, the Data Engineering, Business Intelligence, and Data Analysis teams each developed their own data pipelines to meet their specific demands. The appeal of separate data pipeline architectures lies in their simplicity, clear ownership boundaries, and ease of development. However, Agoda soon discovered that maintaining separate financial data pipelines, each with its own logic and definitions, could introduce discrepancies and inconsistencies that could impact the company’s financial statements. In other words, there is no single source of truth, which is not a good situation for financial data. In this article, we will look at how the Agoda engineering team built a single source of truth for its financial data and the challenges encountered. Disclaimer: This post is based on publicly shared details from the Agoda Engineering Team. Please comment if you notice any inaccuracies. The Problems of Multiple Financial Data PipelinesA data pipeline is an automated system that extracts data from source systems, transforms it according to business rules, and loads it into databases where analysts can use it. The high-level architecture of multiple data pipelines, each owned by different teams, introduced several fundamental problems that affected both data quality and operational efficiency.
See the diagram below:
During a recent review, Agoda observed that differences in data handling and transformation across these pipelines led to inconsistencies in reporting, as well as operational delays. Unblocked: Context that saves you time and tokens (Sponsored)
AI coding tools are fast, capable, and completely context-blind. Even with rules, skills, and MCP connections, they generate code that misses your conventions, ignores past decisions, and breaks patterns. You end up paying for that gap in rework and tokens. Unblocked changes the economics. It builds organizational context from your code, PR history, conversations, docs, and runtime signals. It maps relationships across systems, reconciles conflicting information, respects permissions, and surfaces what matters for the task at hand. Instead of guessing, agents operate with the same understanding as experienced engineers. You can:
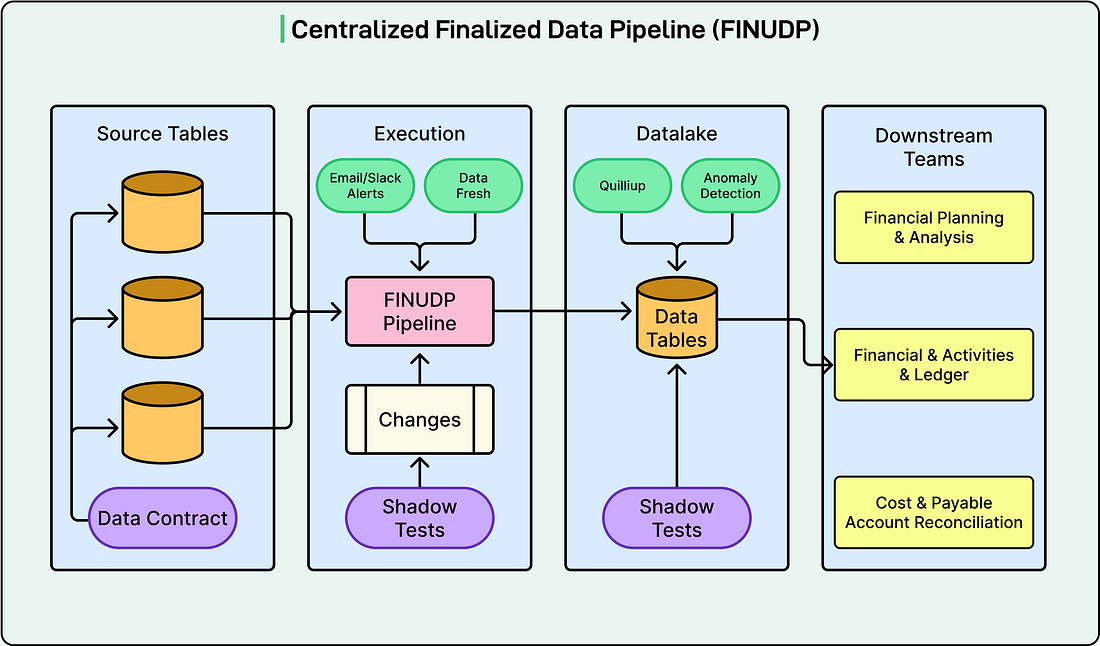
The Solution: Financial Unified Data PipelineTo overcome these challenges, Agoda developed a centralized financial data pipeline known as FINUDP, which stands for Financial Unified Data Pipeline. This system delivers both high data availability and data quality. Built on Apache Spark, FINUDP processes all financial data from millions of bookings each day. It makes this data reliably available to downstream teams for reconciliation, ledger, and financial activities. The architecture consists of several key components.
See the diagram below:
For this centralized pipeline, three non-functional requirements stood out.
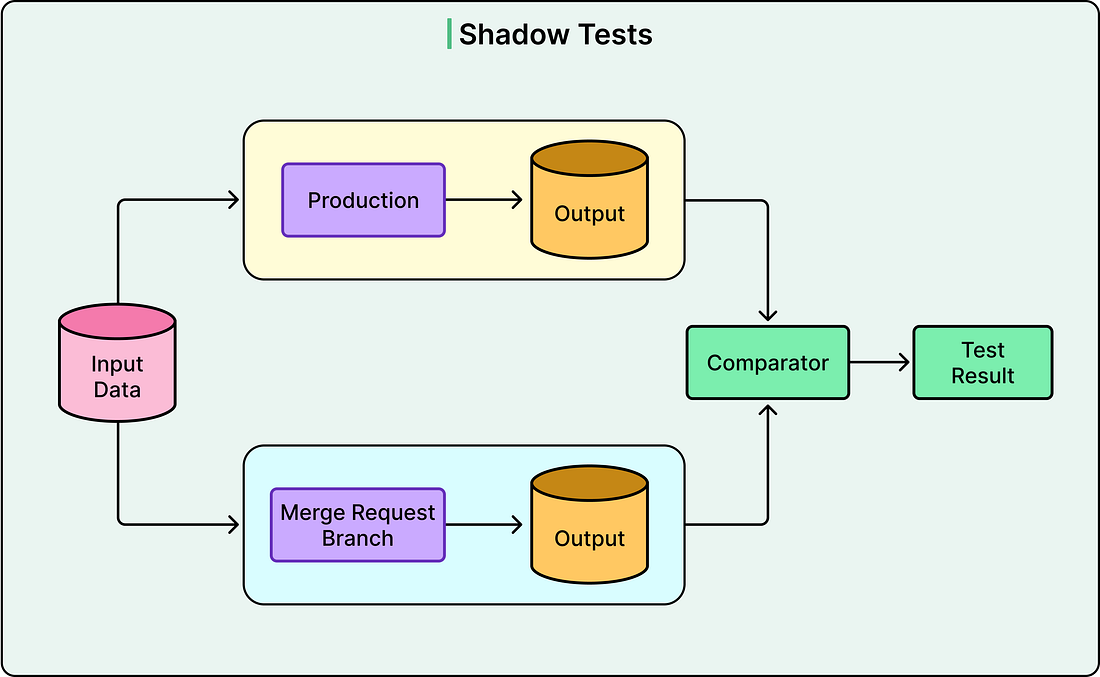
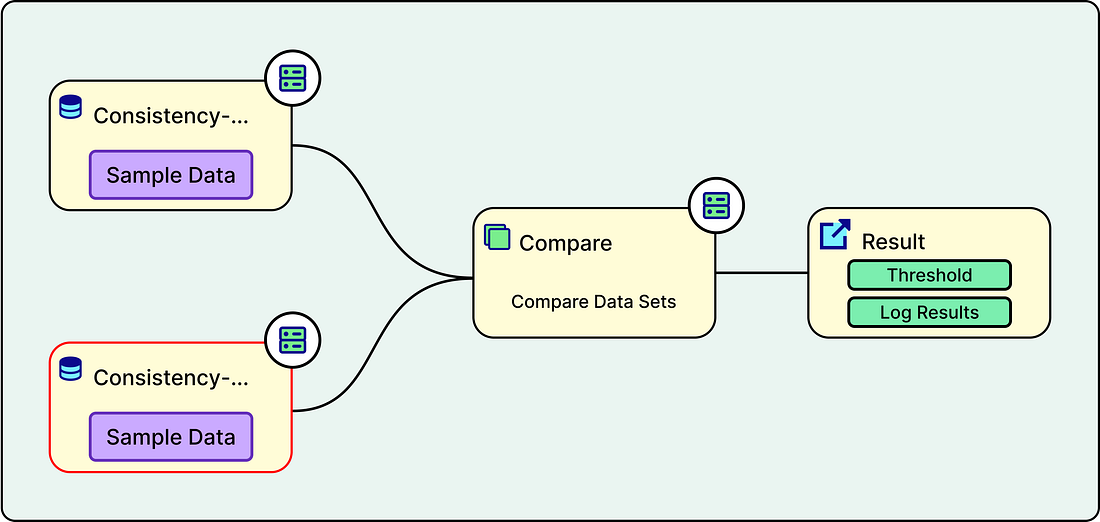
Technical Practices for Quality AssuranceAgoda implemented several technical practices to ensure the reliability of FINUDP. Understanding these practices provides insight into how production-grade data systems are built and maintained. Shadow testing is one of the most important practices. When a developer makes a change to the pipeline code, the system runs both the old version and the new version on the same production data in a test environment. The outputs from both versions are then compared, and a summary of the differences is shared directly within the code review process. This provides reviewers with clear visibility into the impact of proposed changes on the data. It is an excellent way to catch unexpected side effects before they reach production. See the diagram below:
The staging environment serves as a safety net between development and production. It closely mirrors the production setup, allowing Agoda to test new features, pipeline logic, schema changes, and data transformations in a controlled setting before releasing them to all users. By running the full pipeline with realistic data in staging, the team can identify and resolve issues such as data quality problems, integration errors, or performance bottlenecks without risking the integrity of production data. This approach reduces the likelihood of unexpected failures and builds confidence that every change has been thoroughly validated before going live. Proactive monitoring for data reliability includes several mechanisms.
The multi-level alerting system ensures that failures are caught quickly and the right people are notified:
Data integrity is verified using a third-party data quality tool called Quilliup. Agoda executes predefined test cases that utilize SQL queries to compare data in target tables with their respective source tables. Quilliup measures the variation between source and target data and alerts the team if the difference exceeds a set threshold. This ensures consistency between the original data and its downstream representation.
Data contracts establish formal agreements with upstream teams that provide source data. These contracts define required data rules and structure. If incoming source data violates the contract, the source team is immediately alerted and asked to resolve the issue. There are two types of data contracts.
Lastly, anomaly detection utilizes machine learning models to monitor data patterns and identify unusual fluctuations or spikes in the data. When anomalies are detected, the team investigates the root cause and provides feedback to improve model accuracy, distinguishing between valid alerts and false positives. Key Challenges EncounteredThroughout the journey of building FINUDP and migrating multiple data pipelines into one, Agoda encountered several key challenges:
Architectural Trade-offsCentralizing data pipelines came with clear benefits but also required navigating key trade-offs between competing priorities:
ConclusionConsolidating financial data pipelines at Agoda has made a real difference in how the company handles and trusts its financial metrics. Through FINUDP, Agoda has established a single source of truth for all financial metrics. By introducing centralized monitoring, automated testing, and robust data quality checks, the team has significantly improved both the reliability and availability of data. This setup means downstream teams always have access to accurate and consistent information. Last year, the data pipeline achieved 95.6% uptime (with a goal to reach 99.5% data availability). Maintaining such high data standards is always a work in progress, but with these systems in place, Agoda is better equipped to catch issues early and collaborate across teams. References:
|
How Agoda Built a Single Source of Truth for Financial Data
Tuesday, 3 March 2026

Subscribe to:
Post Comments (Atom)











No comments:
Post a Comment