
The right data. The right time.(Sponsored)
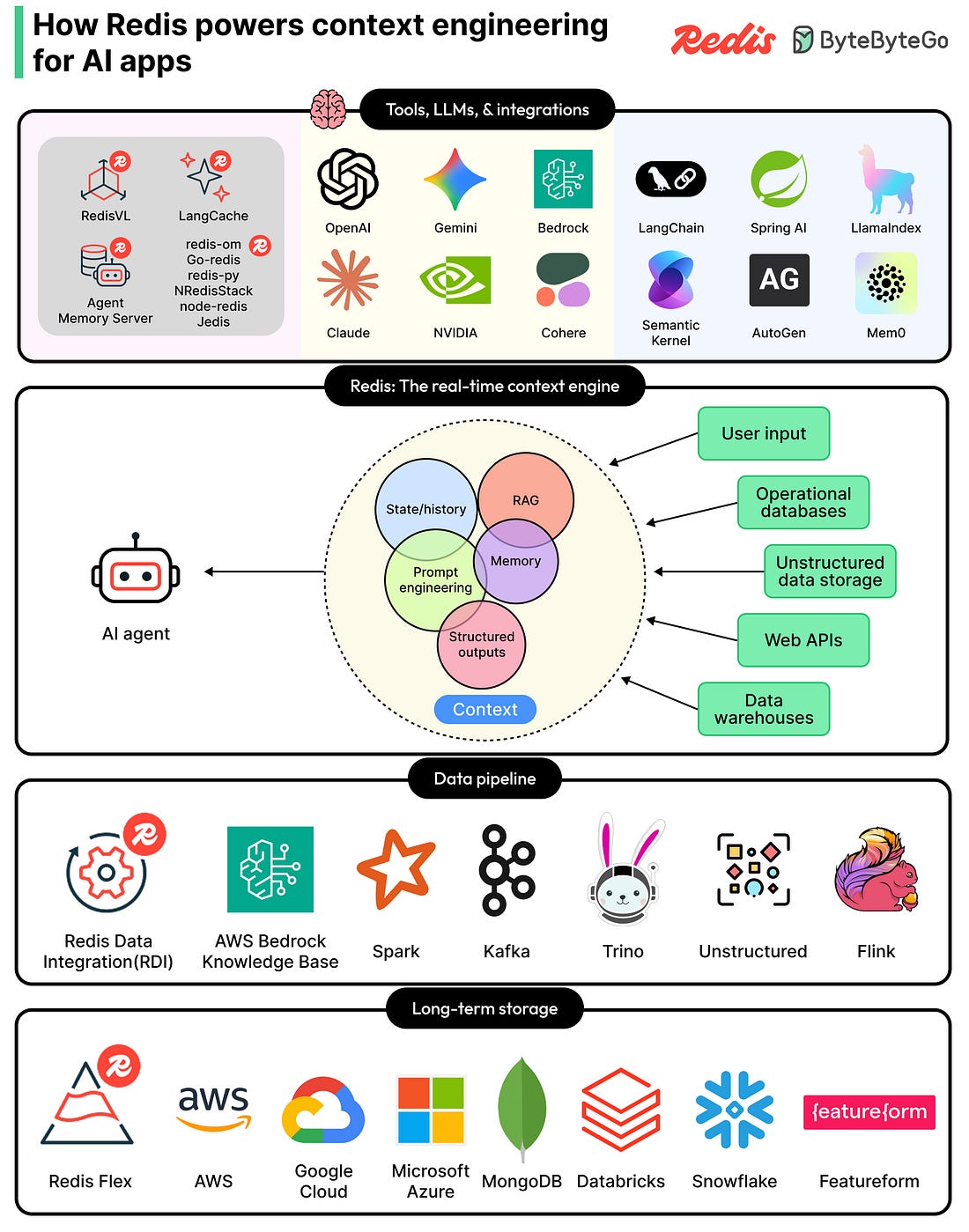
Context engineering is the new critical layer in every production AI app, and Redis is the real-time context engine powering it. Redis gathers, syncs, and serves the right mix of memory, knowledge, tools, and state for each model call, all from one unified platform. Search across RAG, short- and long-term memory, and structured and unstructured data without stitching together a fragile multi-tool stack. With 30+ agent framework integrations across OpenAI, LangChain, Bedrock, NVIDIA NIM, and more, Redis fits the stack your teams are already building on. Accurate, reliable AI apps that scale. Built on one platform. Every time we open X (formerly Twitter) and scroll through the “For You” tab, a recommendation system is deciding which posts to show and in what order. This recommendation system works in real-time. In the world of social media, this is a big deal because any latency issues can cause user dissatisfaction. Until now, the internal workings of this recommendation system were more or less a mystery. However, recently, the xAI engineering team open-sourced the algorithm that powers this feed, publishing it on GitHub under an Apache-2.0 license. It reveals a system built on a Grok-based transformer model that has replaced nearly all hand-crafted rules with machine learning. In this article, we will look at what the algorithm does, how its components fit together, and why the xAI Engineering Team made the design choices they did. Disclaimer: This post is based on publicly shared details from the xAI Engineering Team. Please comment if you notice any inaccuracies. The Big PictureWhen you request the For You feed in X, the algorithm draws from two separate sources of content:
Both sets of candidates are then merged into a single list, scored, filtered, and ranked. The top-ranked posts are what you see when you open the app. The Four Core ComponentsThe diagram below shows the overall architecture of the system built by the xAI engineering team:
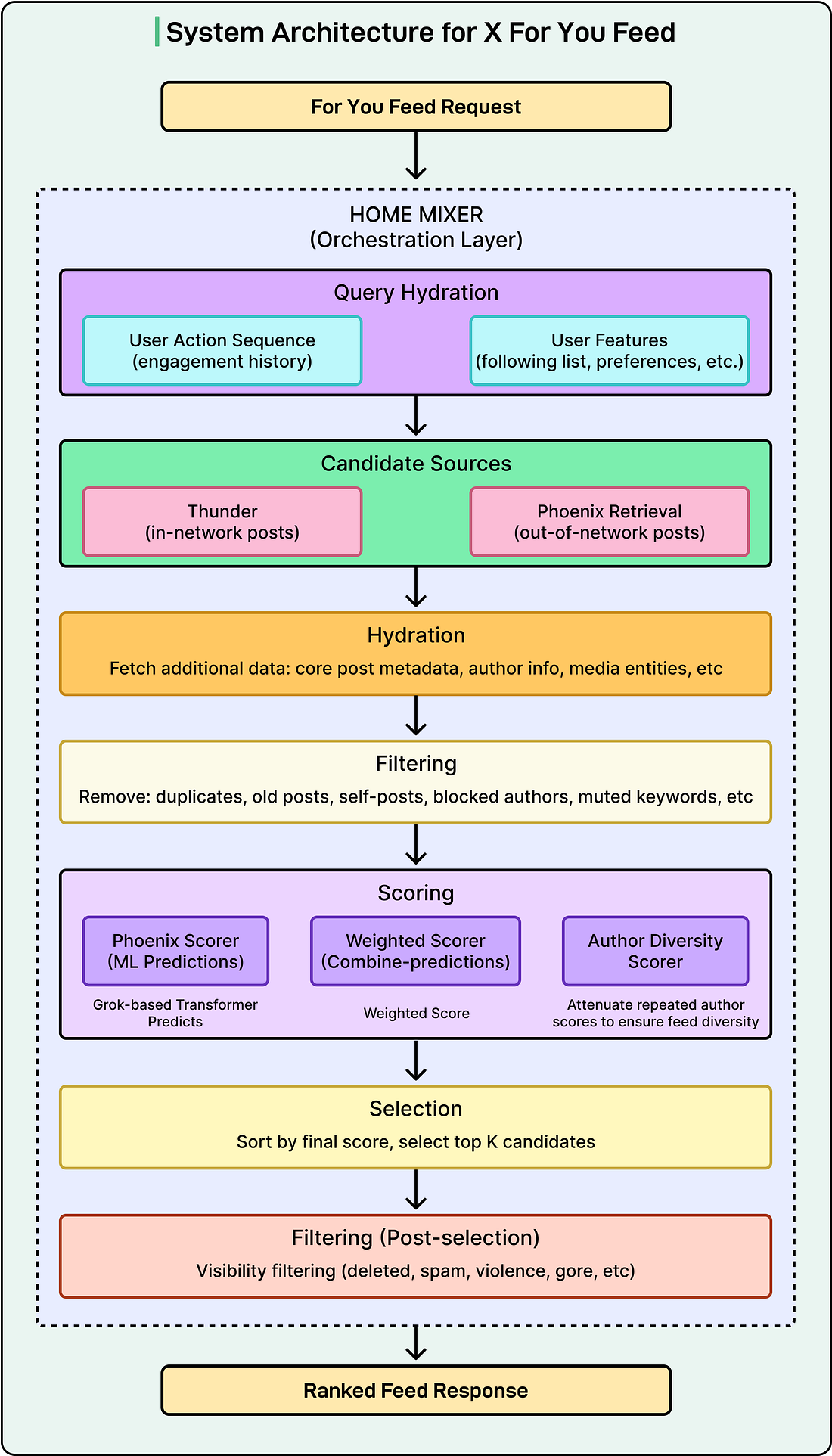
The codebase is organized into four main directories, each representing a distinct part of the system. The entire codebase is written in Rust (62.9%) and Python (37.1%). Home MixerHome Mixer is the orchestration layer. It acts as the coordinator that calls the other components in the right order and assembles the final feed. It is not doing the heavy ML work itself, but just managing the pipeline. When a request comes in, Home Mixer kicks off several stages in sequence:
The server exposes a gRPC endpoint called ScoredPostsService that returns the ranked list of posts for a given user. ThunderThunder is an in-memory post store and real-time ingestion pipeline. It consumes post creation and deletion events from Kafka and maintains per-user stores for original posts, replies, reposts, and video posts. When the algorithm needs in-network candidates, it queries Thunder, which can return results in sub-millisecond time because everything lives in memory rather than in an external database. Thunder also automatically removes posts that are older than a configured retention period, keeping the data set fresh. PhoenixPhoenix is the ML brain of the system. It has two jobs: Job 1: RetrievalPhoenix uses a two-tower model to find out-of-network posts:
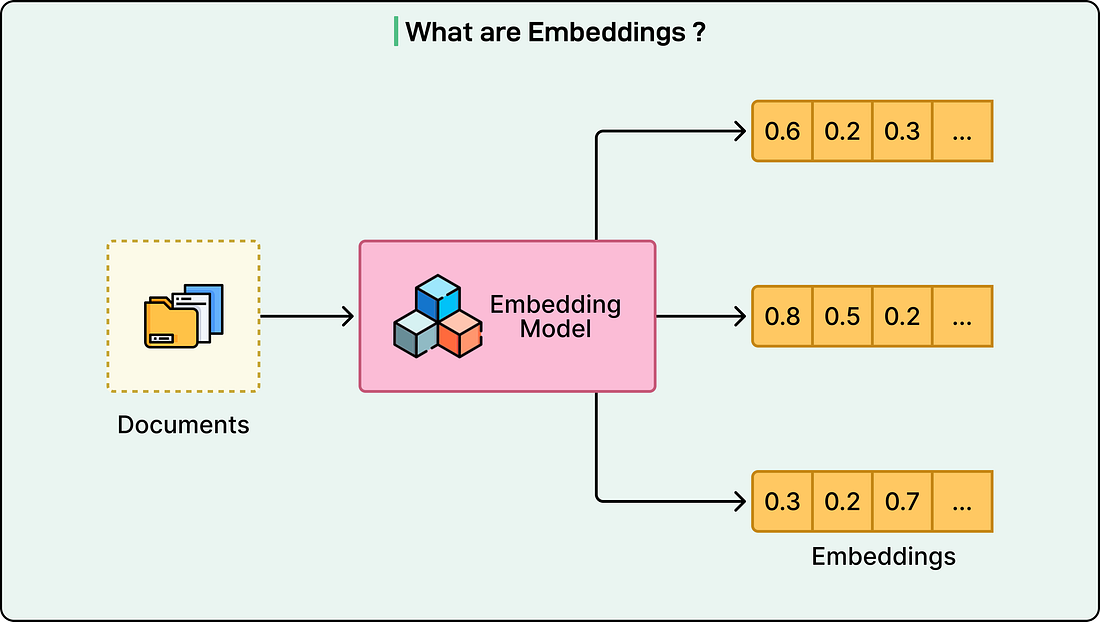
Finding relevant posts then becomes a similarity search. The system computes a dot product between your user embedding and each candidate embedding and retrieves the top-K most similar posts. If you are unfamiliar with dot products, the core idea is that two embeddings that “point in the same direction” in a high-dimensional space produce a high score, meaning the post is likely relevant to you. See the diagram below that shows the concept of embeddings:
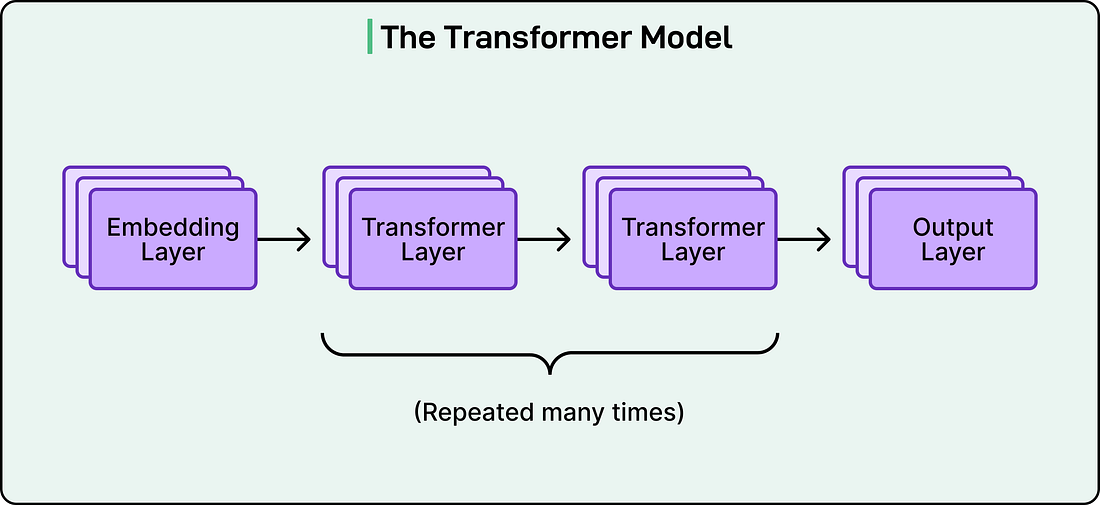
Job 2: RankingOnce candidates have been retrieved from both Thunder and Phoenix’s retrieval step, Phoenix runs a Grok-based transformer model to predict how likely you are to engage with each post. See the diagram below that shows the concept of a transformer model:
The transformer implementation is ported from the Grok-1 open source release by xAI, adapted for recommendation use cases. It takes your engagement history and a batch of candidate posts as input and outputs a probability for each type of engagement action. Candidate PipelineThe Candidate Pipeline is a reusable framework that defines the structure of the whole recommendation process. It provides traits (interfaces, in Rust terminology) for each stage of the pipeline:
The framework runs independent stages in parallel where possible and includes configurable error handling. This modular design makes it straightforward for the xAI Engineering Team to add new data sources or scoring models without rewriting the pipeline logic. The Pipeline Step by StepHere is the full sequence that runs every time you open the For You feed:
How Scoring WorksThe Phoenix transformer predicts probabilities for a wide range of user actions: liking, replying, reposting, quoting, clicking, visiting the author’s profile, watching a video, expanding a photo, sharing, dwelling (spending time reading), following the author, marking “not interested,” blocking the author, muting the author, and reporting the post. Each of these predicted probabilities is multiplied by a weight and then summed to produce a final score. Positive actions like liking, reposting, and sharing carry positive weights. Negative actions like blocking, muting, and reporting carry negative weights. This means that if the model predicts you are likely to block the author of a post, that post’s score gets pushed down significantly. The formula is simple: Final Score = sum of (weight for action * predicted probability of that action) This multi-action prediction approach is more nuanced than a single “relevance” score because it lets the system distinguish between content you would enjoy and content you would find annoying or harmful. ConclusionThere are five architectural choices worth understanding from xAI’s recommendation system:
References:
|
The Algorithm That Powers Your X (Twitter) Post
Wednesday, 25 February 2026
Subscribe to:
Post Comments (Atom)











No comments:
Post a Comment